A 404 code (sometimes referred to as an error 404) is an HTTP status code that indicates an error when accessing a particular web page. It is usually accompanied by a “Page Not Found” error message. This code indicates how the server responded to a request from a user or search engine, specifically telling you that the content of the target page was not found and cannot be displayed. Thus, the 404 code is one of the most common HTTP status codes used to report problems while browsing the Internet.
Similar to the 404 code, there are other codes that convey different statuses. For example, code 301 indicates a permanent redirect, while code 302 is used for a temporary redirect. These codes have different purposes and respond to specific situations in web management or access requests.
What are 404 error pages?
A 404 error page appears when the web page you’re trying to access can’t be found on the website’s server. It’s an HTTP status code response indicating that the requested page is unavailable.
You’ll know you’ve encountered a 404 error when you see messages like:
❌ 404 Not Found
❌ The requested URL was not found on this server
❌ HTTP 404 Not Found
❌ 404 Error
❌ The page cannot be found
Common causes of 404 errors:
🔹 The page no longer exists
🔹 The server is down
🔹 Internet connection issues
🔹 Broken or outdated links
🔹 Incorrectly typed URL
🔹 The page has been moved without redirection
How a 404 error usually occurs
There are several common causes that lead to the 404 code being displayed. These are usually the fault of whoever is creating and maintaining the website, but in some cases, the problem can also be on the user’s side. The most common causes of 404 errors include the following situations:
- Changing the URL of a page – if the URL of a page that is already indexed in search engines is changed, the original link in the search results will lead to a non-existent page. This situation can occur, for example, when the structure of a website is changed, or a page is renamed. If the redirect is not set up correctly, users and search engines will encounter a 404 code.
- Removing a page – If a page, such as a product in an e-store, an article, or a magazine section, is removed from the site, this action can lead to the original link pointing back to a non-existent page.
- Outdated or invalid links – this problem can occur if links, either internal (e.g., links within the site) or backlinks (e.g., links from other sites or old emails), lead to pages that no longer exist or have been moved. These links are considered invalid and result in a 404 error.
- Incorrectly entered URL by the user – Another common cause can be an error on the user’s part, where they enter the URL incorrectly in the address bar, for example, with typos or without the correct structure.
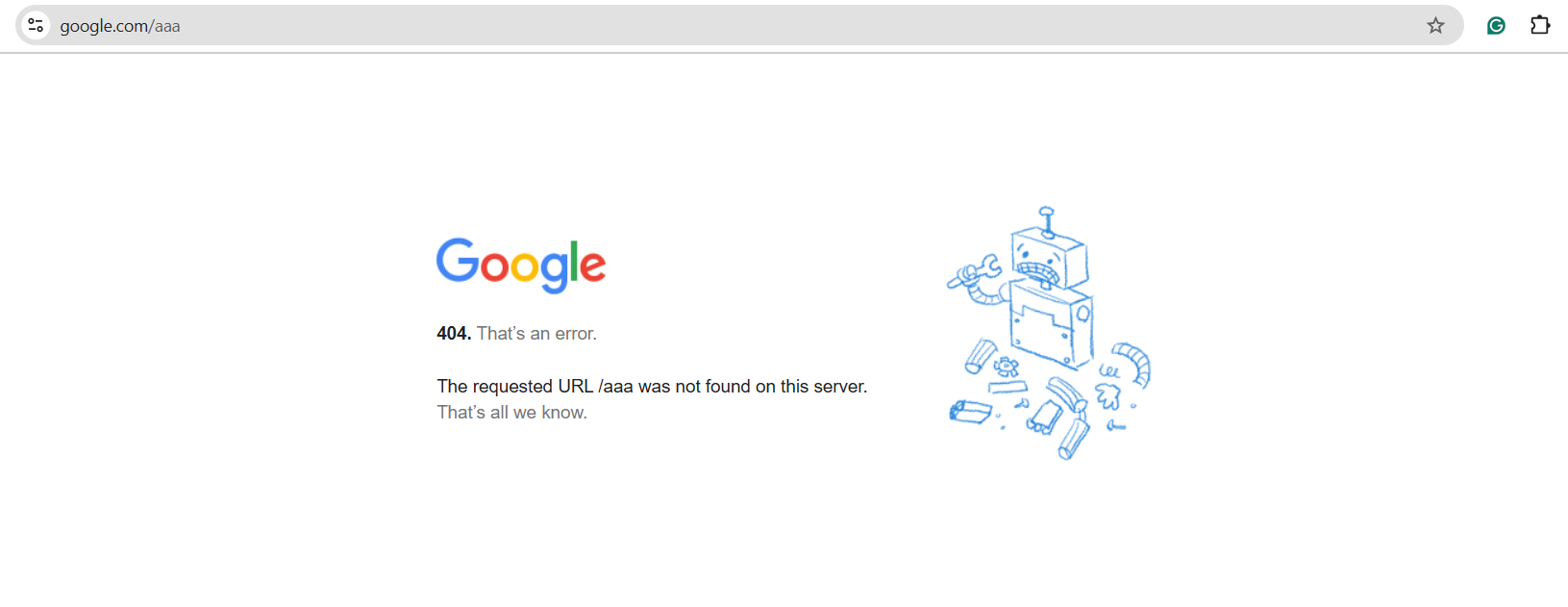
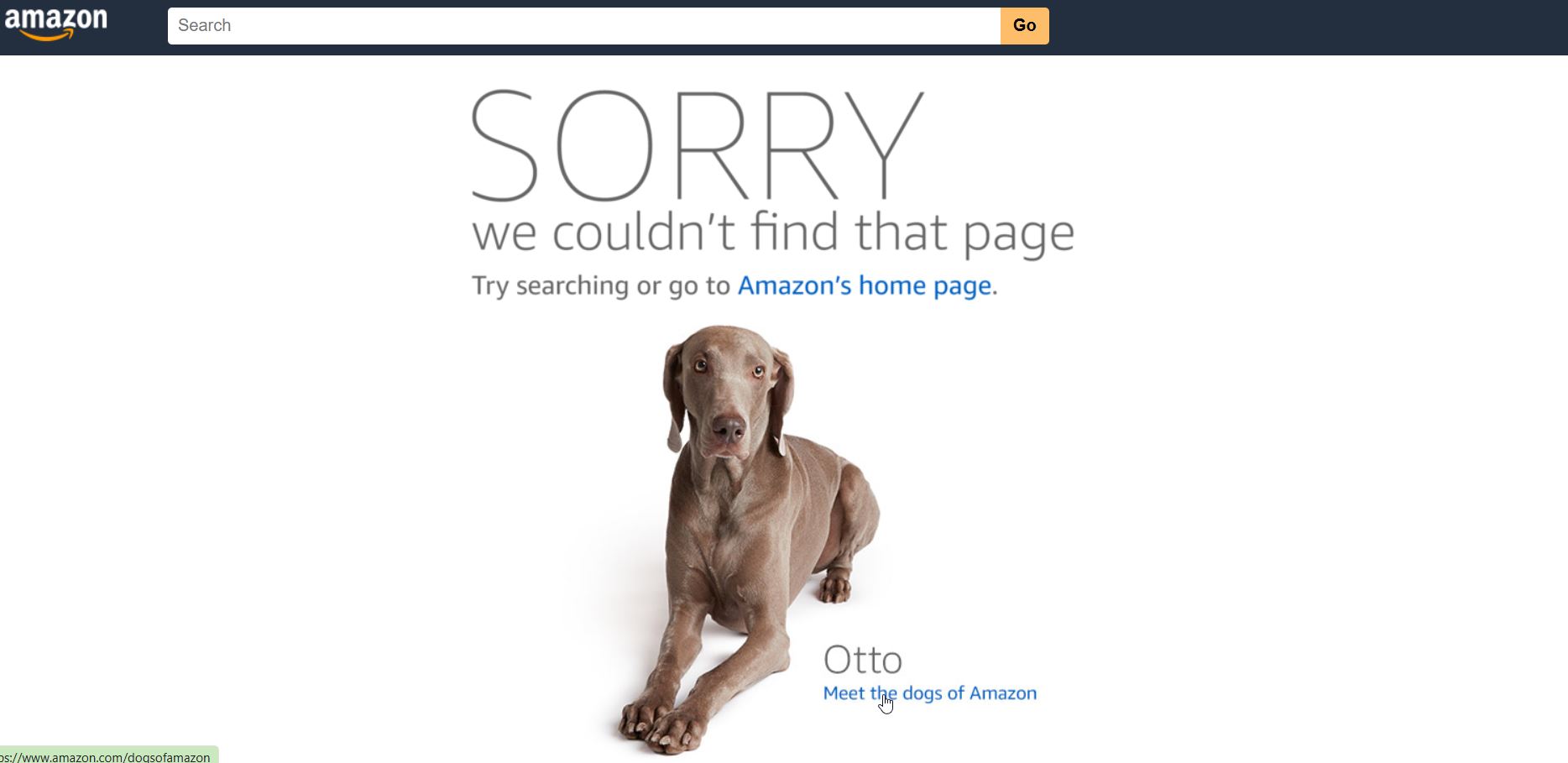
This is a custom 404 error with page not found text from Google
What is a 404 error? A simple explanation
A 404 error is an HTTP status code that means the webpage you’re trying to access cannot be found on the website’s server.
This happens when:
- You enter an incorrect URL in your browser.
- The page has been deleted or moved without a proper redirect.
How a 404 error occurs (step-by-step explanation)
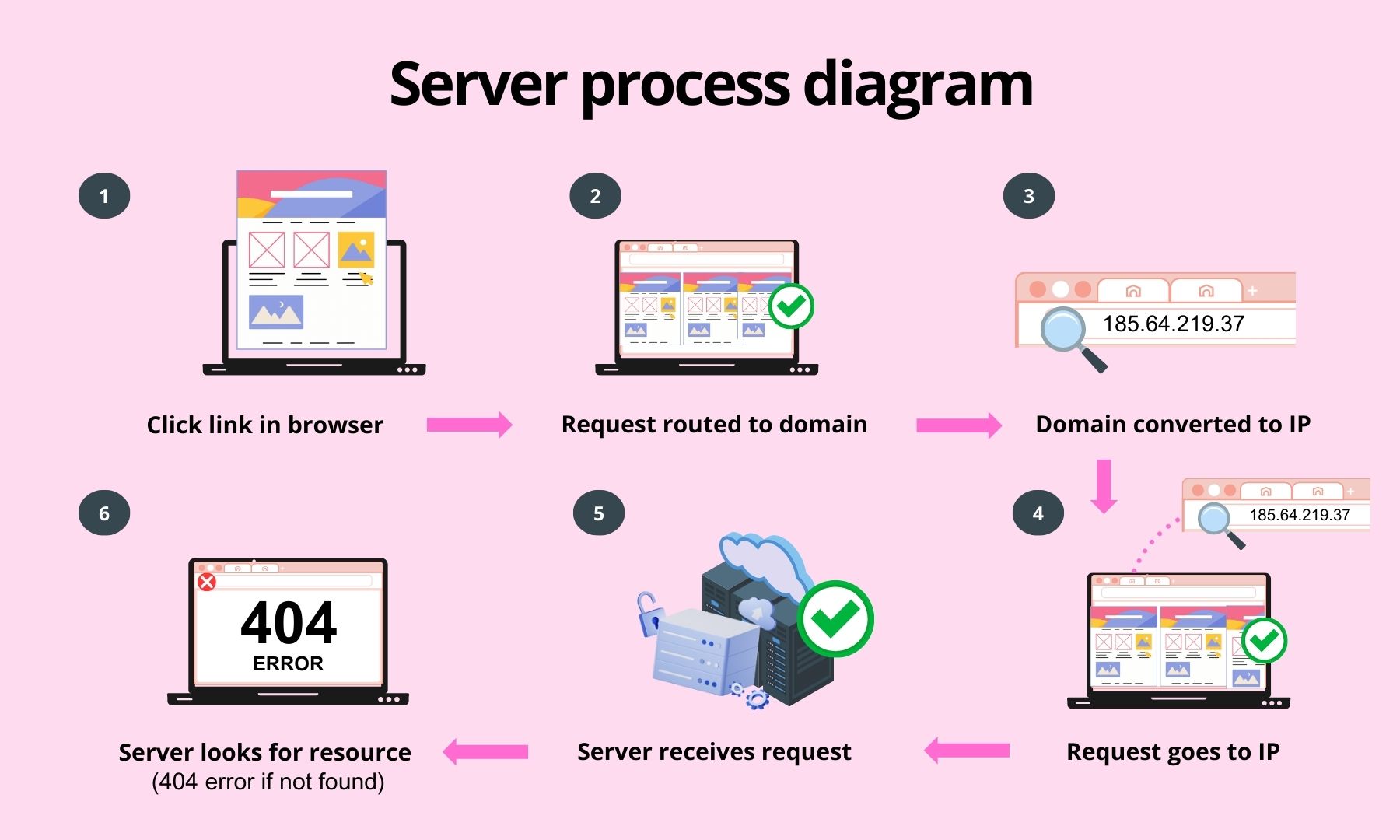
Whenever you enter a URL, your browser sends a request to retrieve the page. Here’s how the process works:
- You click a link or enter a URL in your browser (e.g.,
https://www.krcmic.com/page/).
- Your browser routes the request through the internet to the website’s domain (e.g.,
www.krcmic.com).
- The domain name is converted to an IP address (e.g.,
185.64.219.37).
- Your request is sent to the IP address where the website is hosted.
- A web server receives the request and looks for the requested page.
- If the page (HTML file or PHP file) is missing, the server returns a 404 error message via an error page.
What a 404 error looks like
A 404 error simply means “page not found.” However, websites may display this message in different ways, such as:
- 404 Error
- 404 Not Found
- Error 404
- The requested URL was not found on this server.
- HTTP 404
- 404 File or Directory Not Found
- 404 Page Not Found
- Error 404: The page you’re looking for can’t be found.
Understanding why 404 errors occur helps you fix broken links and improve user experience on your website.
Even the slightest typo in a URL can trigger an HTTP 404 error:
- Case sensitivity – uppercase and lowercase mismatches can break a URL.
- Extra spaces – unintended spaces in the URL can cause errors.
- Trailing slashes – adding or removing a slash at the end may affect accessibility.
- Underscores vs. dashes – using
_ instead of - (or vice versa) can lead to a broken link.
- Other minor variations – even small discrepancies can make a page unreachable.
To reduce 404 errors caused by mistyped URLs, make your permalinks user-friendly by following these best practices:
✅ Keep it short – ideally, 1 to 5 words for easy readability.
✅ Use lowercase only – mixing upper and lowercase increases the risk of errors.
✅ Separate words with dashes – dashes (-) improve readability and reduce typos.
✅ Make it memorable – choose a concise, descriptive URL that clearly represents the page.
A well-structured URL means fewer errors and a better user experience!
Tips for a useful 404 page
If a user gets a 404 error message, it’s important not to lose them completely but to offer them options to navigate and find the content they’re looking for. Experts recommend adding certain elements to the 404 error page that can help the user and improve their experience. The following recommendations can help:
- A link to the home page – users should be able to return to the main page of the site, where they can continue searching for the content they want.
- A link to the FAQ section – FAQs can help users quickly find answers to their questions and make it easier for them to navigate the site.
- Link to relevant section – provide users with links to other related or relevant sections of the site that may be of interest to them.
- Search box – if the page is non-existent, a search box allows users to instantly find what they are looking for.
- Contact information or form – give users the option to contact you if they are unable to find the content they want.
- Site map – a site map helps users better understand the structure of the site and find other relevant information.
- Fun and friendly text – you can add text to make the situation a little “lighter” and lessen the impact of a negative experience. This text should match the overall tone of the site’s communication and be consistent with the copywriting.
Other codes from the 4xx category
In addition to the 404 code, there are several other codes that fall into the 4xx category that you may encounter when developing or maintaining a site. These codes usually indicate errors caused by user requests that the server cannot fulfill. The most common 4xx codes include:
- 400 – Bad Request – this code means that the server does not understand the request that was sent. For example, it could be an error in the format or syntax of the URL. Code 400 can occur for several reasons:
- URL error – the user enters a URL that does not exist or contains incorrect characters, such as unquoted or illegal characters.
- Data Submission Error – the request may contain incomplete or incorrect data. For example, when a form does not contain the required data or the wrong file format is sent.
- Incorrect request headers – the server is expecting a certain header or information that is not present or is in the wrong format.
- This code is commonly used for diagnosing errors in web applications or when interacting with APIs where requests need to be formatted correctly.
- 401 – Unauthorized – this code indicates that the user has not met the conditions for accessing the site, for example, if they have entered the wrong login credentials or their IP address is not accepted. The 401 code is often used in these cases:
- Incorrect login – the user enters an incorrect username or password.
- Unauthorized access to a protected area – if a page or area on the site is protected by access permission and the user is not properly logged in or does not have sufficient permissions.
- IP address not accepted – some websites and servers may have restricted access based on IP address. If the user’s IP address is not in the list of allowed addresses, the server will return this code.
- This code is important for sites that contain sensitive or private information and is often used in administrative panels or applications that require authentication.
- 403 – Forbidden – this code indicates that the server cannot fulfill the request because the user does not have the necessary permissions to access the page. This code differs from 401 in that even though the user may be authenticated (for example, logged in), the server will still deny access. Code 403 occurs in the following cases:
- Insufficient permissions – a user may have a properly logged-in account but not have the necessary permissions to access a particular page or feature.
- Access denied for certain IP addresses or geographic areas – servers may block access based on IP address or geographic location, which may result in a 403 error.
- File or folder with incorrect permissions – the site administrator may set files or directories to be restricted to the public or certain types of users.
- This code is often used for sensitive parts of the site, such as administrative areas or controlled access to data.
- 407 – Proxy Authentication Required – this code indicates that the request cannot be processed without proxy authentication. Common causes include:
- Proxy server requires authentication – if a site or application uses a proxy server for content filtering or security purposes, the server may require the user to authenticate through the proxy server before the request is processed.
- Incorrect proxy server configuration– if the server is not properly configured to authenticate users through the proxy, you may receive a 407 error.
- This code is commonly used in corporate environments where proxy servers are used to manage Internet access.
- 408 – Request Timeout – this code appears when a request takes longer than the server can provide. The server did not receive a response within the prescribed time, and the request was canceled.
- Long page load time – if the server does not receive a response from the user or application in the required time, for example, due to server congestion or poor network connectivity, the server returns this code.
- Slow Internet connection – if the user has a poor Internet connection, the request may not run in time, and the server may reject it.
- Request processing delay – if the server has to process a very complex request, for example, when generating a large volume of data, this can lead to timeouts.
- This code is useful for diagnosing performance issues on the web or in applications.
Best 404 page designs – how should a 404 page look like?
There are two main types of 404 pages:
- Generic 404 error pages
- Custom 404 error pages
Generic 404 error page
A generic 404 page is the default error page displayed when a requested webpage cannot be found on a website. It is typically plain and unhelpful, often showing only a basic message such as “404 Not Found” or “The requested URL was not found on this server.”
Generic 404 pages look this:
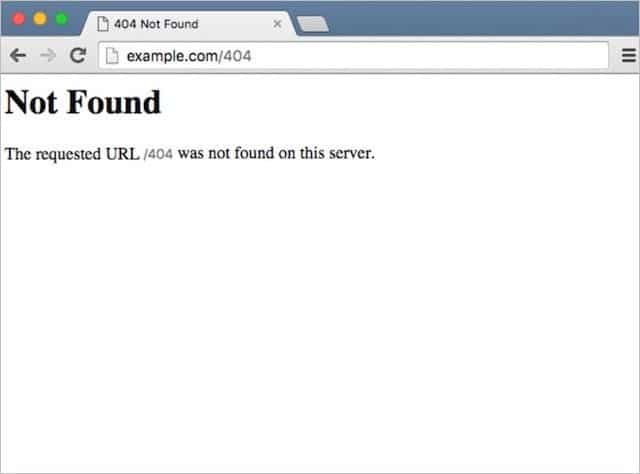

The trouble with generic 404 pages is the user experience sucks.
Key characteristics:
❌ Lacks clear navigation – does not provide guidance on what to do next. They use complex technical jargon, provide no clear direction, and push users away from your site.
❌ Minimal design – often just a text-based message from the web server.
❌ Frustrating for users – leads to higher bounce rates as visitors may leave the site.
❌ No branding or engagement – doesn’t align with the website’s look and feel.
Custom 404 pages – why custom 404 pages matter (and how to make them work for you)
A custom 404 page offers several benefits:
- Reduces customer frustration.
- Strengthens branding and improves navigation.
- It can even lead to conversions in some cases.
Many website owners see custom 404 pages as an afterthought. After all, if you’ve already minimized broken links and errors, why invest time and effort into a page that (hopefully) few visitors see?
Here’s the thing – a well-designed 404 page can improve SEO, enhance user experience, and even boost conversions.
Let’s explore why custom 404 pages are essential and how they can turn lost visitors into engaged users.
Search engines discover essential pages
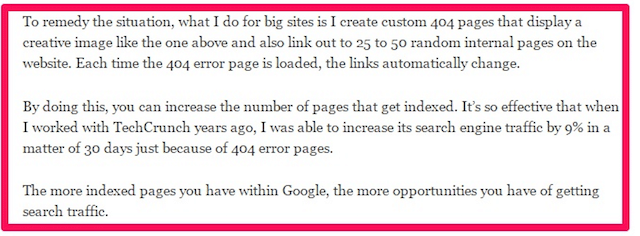
If you manage a large website, broken links are inevitable. And with a limited crawl budget, search engines may miss crawling your most valuable pages.
A custom 404 page can help by strategically linking to key pages you want indexed.
🔹 Create a list of priority pages (e.g., high-converting landing pages or important blog posts).
🔹 Use a script to randomly insert links to these pages on your 404 page.
Because search engine crawlers frequently visit 404 pages due to inbound links, this technique increases the chances of indexing important content.
✅ Case study: Neil Patel used this strategy on TechCrunch and increased search traffic by 9%! 🚀
Strengthen branding and keep visitors engaged
A generic 404 page is jarring. Visitors might think they’re on the wrong website or that something is broken beyond repair.
👎 Bad user experience = higher bounce rates.
A branded 404 page helps reassure users they’re still in the right place:
✅ Use your website’s branding – keep the header, navigation, fonts, and colors consistent.
✅ Add a friendly message – instead of a dull “Page Not Found,” try a humorous or helpful approach.
✅ Include a search bar – to help users quickly find what they were looking for.
When visitors recognize they’re still on your website, they’re more likely to stick around.
Turn frustration into engagement (or even fun!)
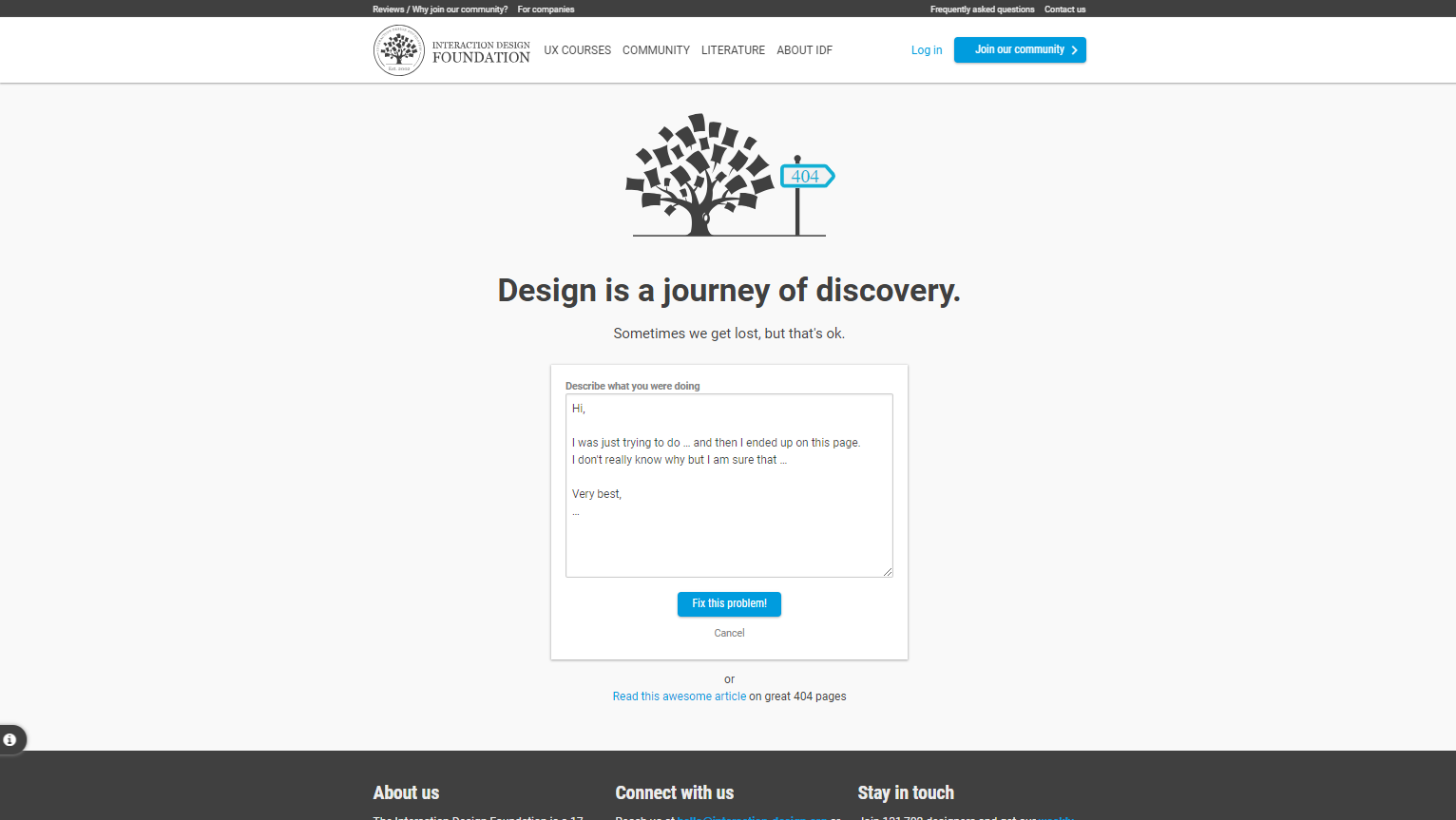
The Interaction Design Foundation offers visitors the option to send an email explaining what they were doing when they landed on the 404 page and what they expected to find. While well-intentioned, this approach isn’t the most effective. A better strategy would be to analyze website error logs or use website crawling tools to proactively identify and fix common navigation issues, ensuring users reach their intended destinations more efficiently.
Nobody likes seeing a 404 error, but a well-crafted custom 404 page can transform frustration into a positive experience.
Some ways to engage visitors on a 404 page:
🎮 Mini-games – some websites embed simple games to keep users entertained.
😂 Humor – a witty message or a fun visual can lighten the mood.
🎨 Creative design – unique and interactive elements make users remember your site.
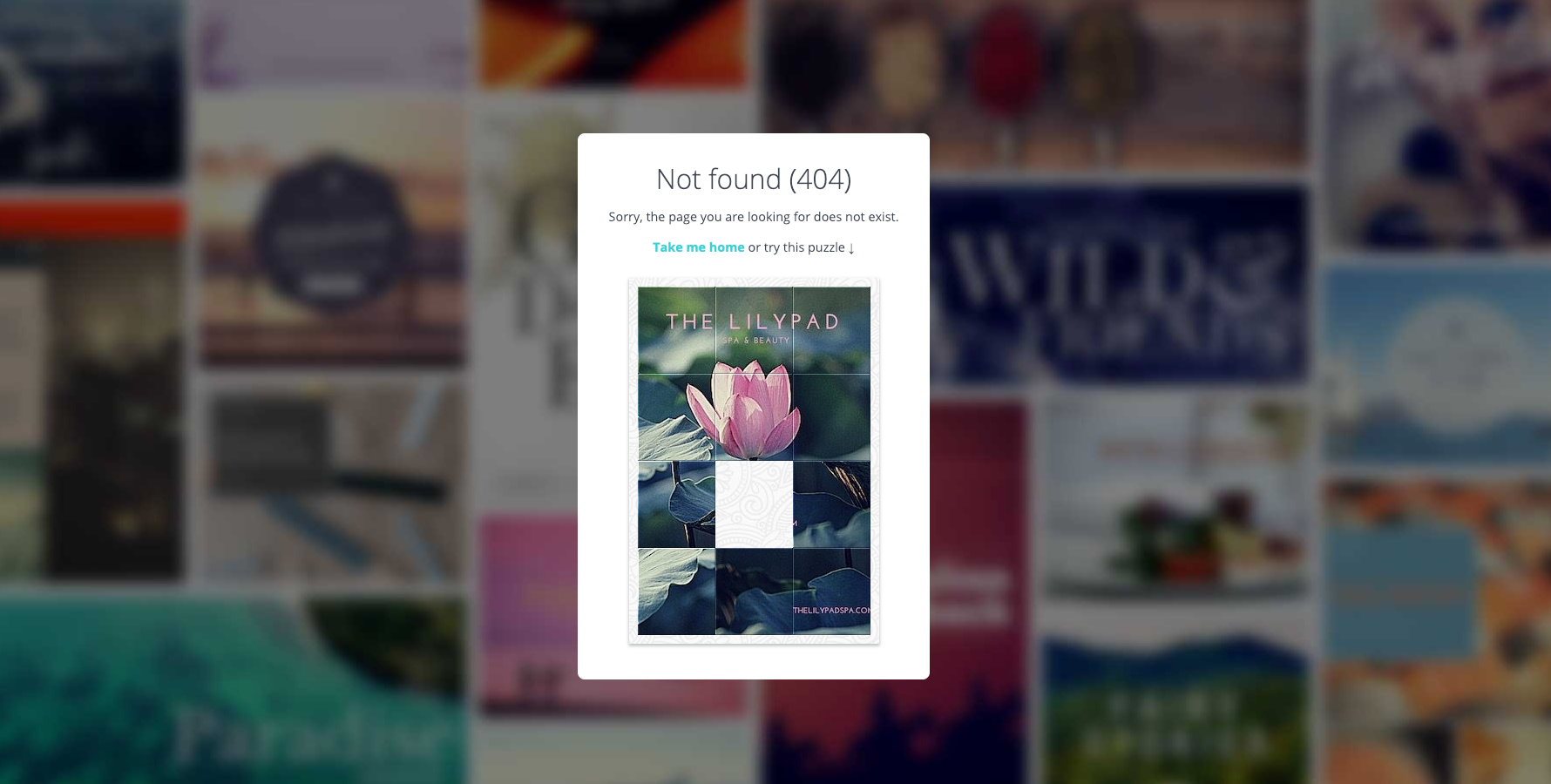
Adding a small interactive game can be a great way to engage lost visitors—if you have the time to create one. It’s a clever touch that makes your 404 page stand out!
Guide visitors to relevant content (instead of letting them leave)
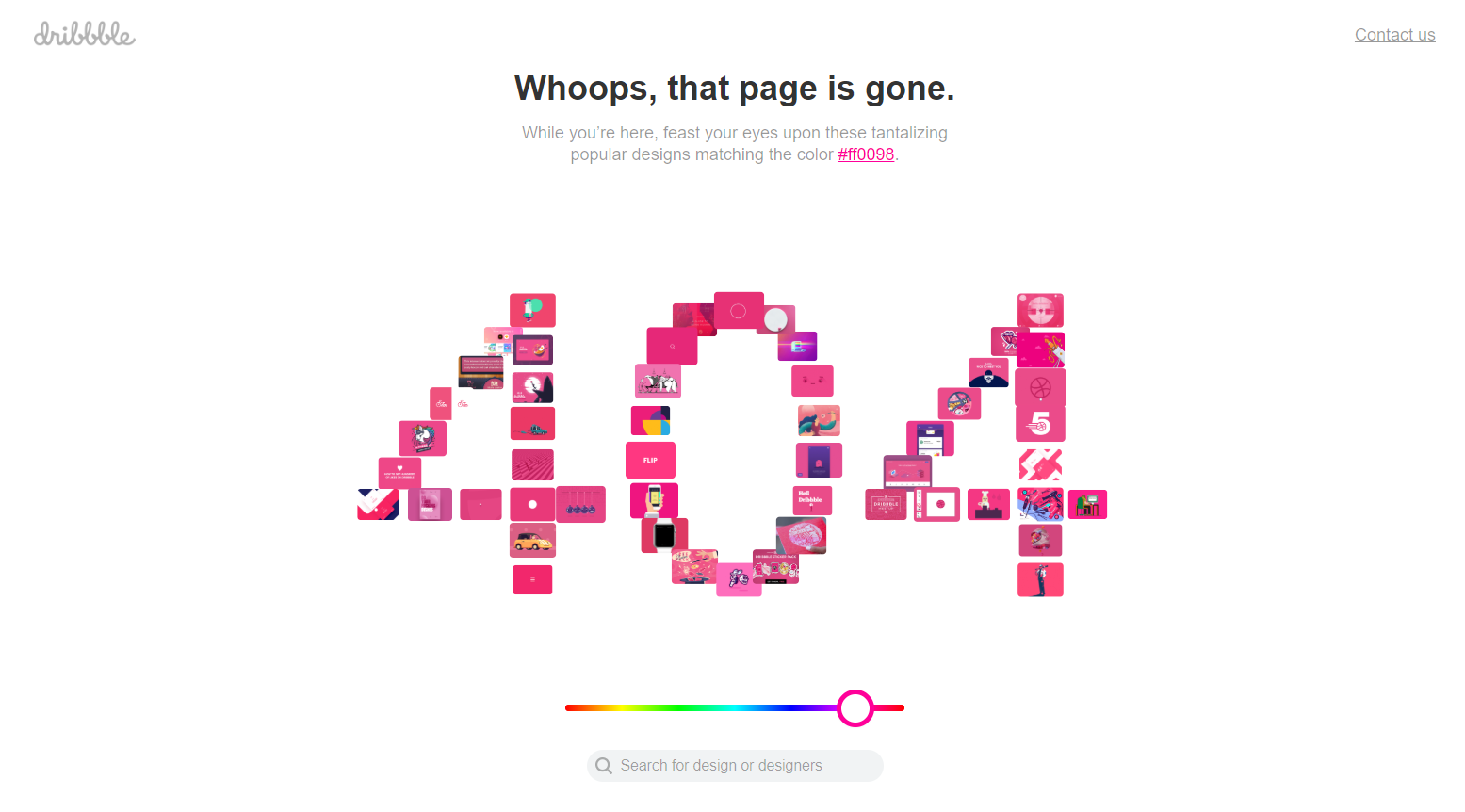
Dribbble, a platform for designers seeking inspiration, takes a smart approach to its 404 page by allowing lost visitors to select a color and browse designs in that shade. This is a great example of a website that truly understands its audience and ensures they still find relevant content, even when landing on an error page.
A generic 404 page is a dead end – it gives users no direction and drives them away.
A custom 404 page can redirect users to other valuable pages, such as:
🔹 Popular blog posts
🔹 Product categories
🔹 Help center or contact page
🔹 Homepage or key landing pages
When users have a path forward, they stay on your site longer – which means lower bounce rates and higher engagement.
Turn lost visitors into conversions
Did you know a 404 page can drive sales and lead generation?
💡 How? By adding an incentive.
Some ideas to turn a 404 into a conversion opportunity:
🛒 Offer a discount – you can include a 20% off coupon on their 404 page, which can increase purchases and add-to-cart rates.
📩 Use a lead magnet –you can offer a free case study in exchange for an email address, helping them capture leads even from lost traffic.
A simple tweak to your 404 page can turn missed opportunities into revenue!
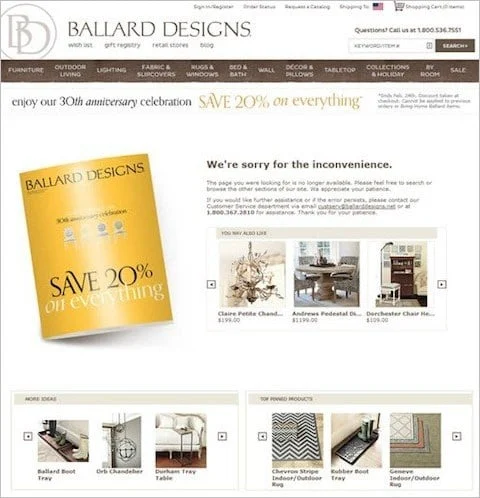
According to Which Test Won, this older version of 404 error page of eshop Ballarddesigns.com, featuring product recommendations and a 20% discount code, resulted in higher total purchases and an increased add-to-cart rate.
You can also leverage your 404 page to showcase a lead magnet (this example will show the users popup trying with 60 % discount):

Final thoughts: why custom 404 pages matter
A custom 404 page is more than just a courtesy – it’s an SEO and user experience asset that can:
✅ Help search engines crawl essential pages.
✅ Strengthen your brand identity and engagement.
✅ Turn frustration into a fun, memorable experience.
✅ Keep users on your site by guiding them to relevant content.
✅ Even drive conversions and revenue!
If you haven’t optimized your 404 page yet, now’s the time. A little effort can go a long way in improving your website’s performance and user retention.
🚀 Need help designing a high-converting 404 page? Contact me at info@krcmic.com, and let’s create one that works for you!
How 404 errors affect usability and SEO – why they’re harmful
If you’ve ever heard that 404 errors don’t impact your SEO, you’re not alone. Even Google states that “404 errors don’t affect your site’s rankings”. But here’s the truth – while 404s themselves may not directly harm rankings, their impact on link equity, crawl efficiency, and user experience can be detrimental.
Let’s break down how 404 errors can hurt your website and what you can do to fix them.
How 404 errors negatively impact your website
Broken links = lost ranking signals
When other websites link to yours, those inbound links pass link equity (SEO value) to your pages. But if those links point to non-existent pages (404 errors), the ranking potential doesn’t fully pass through – or worse, is entirely wasted.
This means that:
❌ You lose valuable SEO benefits from backlinks.
❌ Pages that could rank higher fail to reach their potential.
❌ Your domain’s overall authority can suffer.
404 errors waste your crawl budget
Search engines allocate a crawl budget – a limited number of pages they will scan on your site within a certain period. Too many 404 errors waste this budget, meaning Googlebot might not reach your most important pages.
If Google prioritizes crawling dead links instead of valuable content, you could experience:
❌ Delayed indexing of new or updated content.
❌ Lower visibility for key landing pages.
Poor user experience = higher bounce rates
Imagine clicking on a link expecting helpful content, only to land on a generic “404 Not Found” page. Frustrating, right?
When visitors hit 404 pages:
❌ They leave your site (high bounce rate).
❌ They lose trust in your brand.
❌ They might not return, costing you potential conversions.
Reducing 404 errors = a smoother user experience + better retention rates.
How to find 404 errors on your website
Before you can fix 404 errors, you need to find them. Here are the best tools to identify broken links:
- Screaming Frog – run a site audit, filter by 4XX errors, and get a complete list of 404 pages.
- Google Search Console – navigate to Coverage > Excluded > Not found (404) to see Google’s detected errors.
- Ahrefs & SEMrush – use their site audit tools to uncover broken internal and external links.
- Google Analytics 4 – GA4 automatically tracks 404 error responses. You can quickly access this data by searching for your error page in the Pages and Screens report section. However, your 404 error pages must be properly configured.
How to fix 404 errors – 3 best solutions
Redirect the broken page (recommended)
🔄 301 Redirect the broken page to a relevant existing page. This ensures users and search engines reach the correct content while preserving SEO value.
📌 Example: A deleted product page can redirect to a related product or the main category page.
⚠️ Avoid irrelevant redirects! Sending users to unrelated pages (e.g., redirecting all 404s to the homepage) can hurt user experience and SEO rankings.
Restore the page (if still valuable)
If a deleted page still gets traffic or backlinks, consider bringing it back instead of redirecting it.
✅ Recover it from an old backup if available.
✅ Use the Wayback Machine to recreate the lost content.
✅ Update it with fresh information to keep it relevant.
Correct the broken link
For internal links, simply edit the URL in your website’s content to point to the correct page.
For external links (backlinks from other websites), reach out to the site owner and ask them to update the link. Many website owners are happy to fix broken links, as it improves their own site’s usability.
Optimizing your 404 page – how to turn lost traffic into opportunity
Even after fixing your broken links, some 404 errors are unavoidable. Instead of leaving users stranded, create a custom 404 page to keep them engaged.
🔹 Include a friendly message (not just “Page Not Found”).
🔹 Add a search bar so visitors can find what they need.
🔹 Suggest related pages to guide them back to useful content.
🔹 Keep branding consistent to maintain trust and recognition.
A well-designed custom 404 page can turn a dead-end into a conversion opportunity.
Best designs and examples of 404 pages
Keep your 404 error page/message simple

It may seem obvious, but clarity is key when designing a 404 page.
The problem with generic 404 error pages is that they often use technical jargon – and let’s be honest, most users have no idea what an “HTTP 404” means.
🔹 Avoid confusing terms and use clear, user-friendly language.
🔹 A message like:
👉 “Sorry, the page you’re looking for doesn’t exist.”
…works perfectly.
If you want to add more context, explain why the error might have occurred – but carefully.

❌ Don’t sound like you’re blaming the user!
Instead of saying:
🚫 “This error occurred because…” (which may seem accusatory),
Try:
✅ “You may be seeing this page because…”
✅ “You might have landed here due to…”
Here’s a great example from X-Cart, where they clearly outline possible reasons for the error.
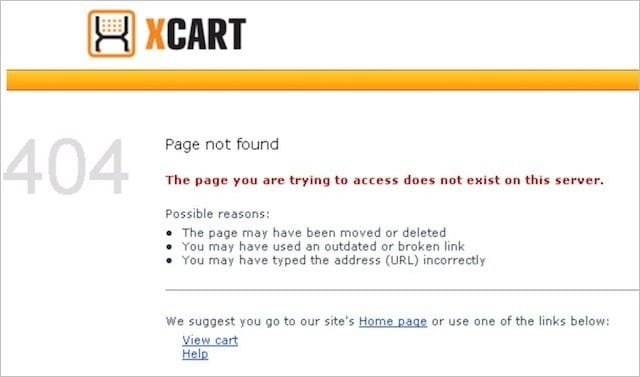
Ensure your 404 error page matches your brand
I’ve said this before, but it’s worth repeating – your 404 page should feel like part of your website.
That means it should include:
✅ Your logo
✅ Your website’s color scheme
✅ Your fonts and design style
When users land on your 404 page, they should immediately recognize they’re still on your site.
If your 404 page looks out of place, visitors might assume they’re lost and leave your site altogether – which is exactly what you want to avoid.
Guide 404 visitors back to your homepage
A simple yet effective strategy is to provide a direct link to your homepage from your 404 page.
Your homepage serves as a navigation hub where users can explore your content, services, or products.
All it takes is a clear call-to-action button or link encouraging users to return to the homepage – just like Bloomberg does with their 404 page.
Link to your most popular content
You worked hard to get visitors to your site. Don’t lose them to a dead end!
Instead, offer links to your most visited pages – this could be:
🔹 Trending blog posts
🔹 Popular product pages
🔹 Key service pages
A quick look at Google Analytics can help you identify your highest-performing content to feature on your 404 page.
For example, in Hootsuite, you can see links to other features, price models, and blog posts.
The goal? Give visitors something valuable to click on, plus there is some probability that they will stay longer on your site or get interested in the products/services you offer.
Add a search box to your 404 page
Even with helpful links, some users won’t find what they need – and you don’t want them leaving frustrated.
A simple search bar can solve this problem by allowing users to find the exact content they are looking for.
Most CMS platforms like WordPress, Shopify, and Wix already have built-in search functionality, so implementing this is a no-brainer.
🔍Or you can try to show the users some suggestions (like if they make typo, you can try to offer them the correct page/directory if that page exists)
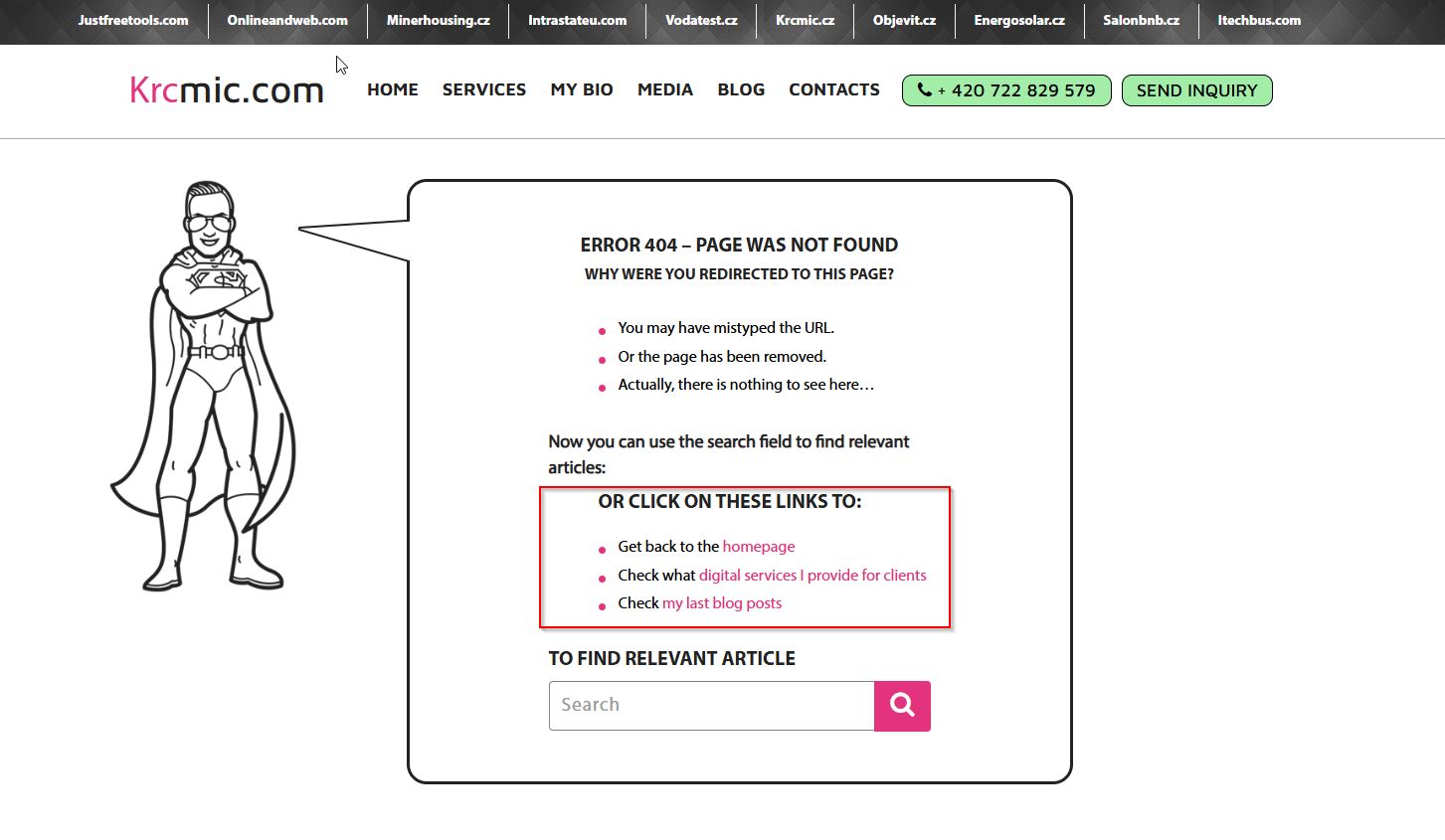
404 page design – less clutter = higher success rates
As I’ve mentioned before, adding popular links to your 404 page can be beneficial.
But that doesn’t mean you should overload it with every link imaginable and hope visitors click on something.
❌ That is a bad idea.
Overwhelming users with too many choices can cause frustration, leading them to leave your site entirely.
Numerous studies confirm that the more options you present, the harder it is for users to make a decision. This is known as the paradox of choice – and you definitely want to avoid it.
Instead, keep your design clean and limit the number of actions available.
✅ Try to find the perfect balance, offering only the most important internal links on a clean, simple layout.
Include your contact details
For most business websites, the goal is to convert visitors into customers.
And what’s the most effective way to do that? Human interaction.
A BIA/Kelsey study found that phone calls convert 10-15x more than web leads.
Yet, many websites bury their contact details – if they include them at all.
Now, consider this: users landing on your 404 page are already frustrated because they couldn’t find what they were looking for.
Would you want to add another barrier that makes it even harder for them to reach out?
Of course not!
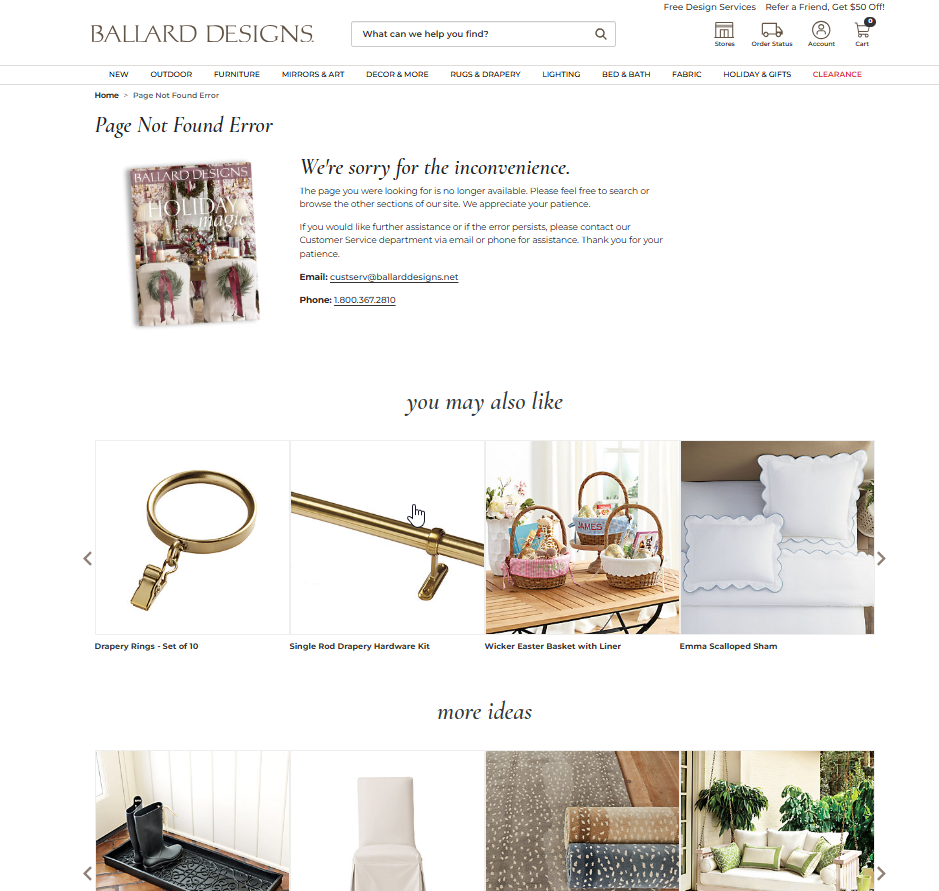
This is how now look like the current version of the 404 page of furniture shop Ballard Designs (we were already shown the older version above with discounts incentives).
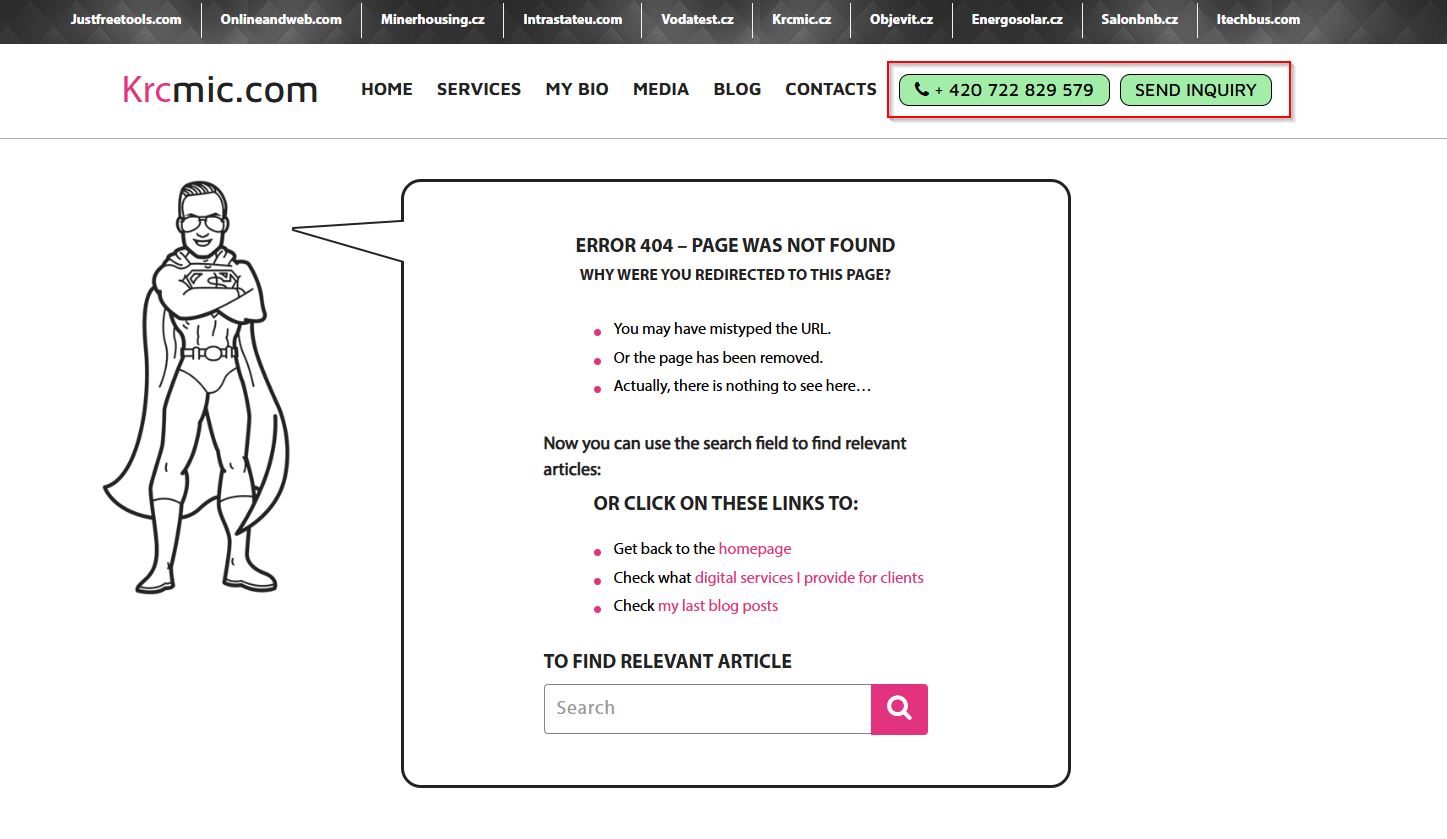
To minimize frustration and show users you care, prominently display your contact information on your error page.
For example, we include:
📞 Our phone number
💬 Live chat support
The channels you choose are up to you, but make sure they’re visible and accessible.
Display consistent header and footer navigation
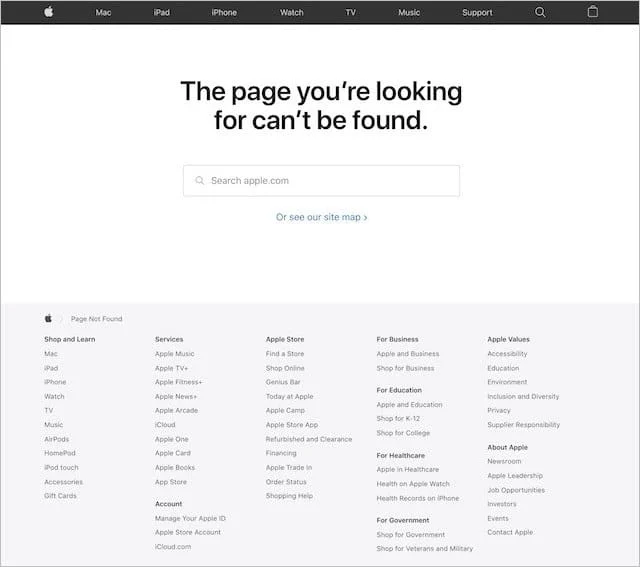
Another best practice is including your standard website navigation – header and footer – on your 404 page.
Just like adding popular links, this ensures that users can easily navigate back to key sections of your site.
🚀 Apple does this well by keeping their navigation intact on their 404 page, ensuring a seamless experience.
Even better? This also keeps the 404 page visually consistent with the rest of your website, which helps reduce bounce rates.
Translate your 404 page into multiple languages
Let’s face it . 404 errors are confusing enough without the added barrier of an unfamiliar language.
If your website serves multiple languages, your 404 page should, too.
The best approach?
✅ Create separate 404 pages for each language – depending on your website structure, it the localized content and design can be implemented to the different subdirectories
layout\en\404.html
layout\de\404.html
or final URLs:
layouts\404.html (as default language)
layouts\404.de.html (for a German version of 404 page)
✅ Automatically detect the user’s preferred language and display the correct version
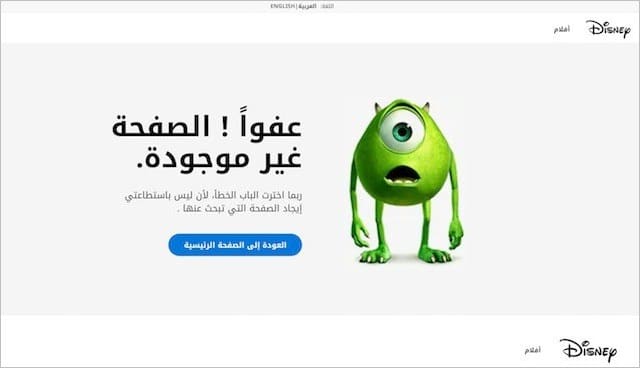
People prefer consuming content in their native language, and doing this will increase engagement and trust.
🎯 Disney does a fantastic job with this, ensuring their 404 pages are available in multiple languages for their diverse audience.
Make an offer with exit-intent popups

Exit-intent technology is rarely used on 404 pages – but it absolutely should be.
🔹 It reduces bounce rates
🔹 It increases conversions
🔹 It’s easy to set up using tools like OptinMonster or Sumo
How does it work?
📌 Exit-intent technology detects when a user is about to leave your 404 page and triggers a popup offer before they go.
Example use cases:
- 💸 Offer a discount code for first-time visitors
- 🎯 Promote a free consultation
There are endless possibilities – so get creative!
A well-timed popup can help retain up to 70% of users who would have otherwise left your site for good. But it does not have to be always popup.
Instead of relying solely on popups, you can implement dynamic elements that automatically display discount codes or highlight categories with massive discounts based on user behavior.
This approach feels more seamless and user-friendly, reducing the chance of annoying visitors with intrusive popups. However, you must also be cautious—such automated discount displays can be easily exploited by regular users who repeatedly trigger the function to access discounts they were not meant to see.
⚠️ Why does this matter?
If not properly monitored, this loophole can lead to:
- Revenue loss due to excessive, unintended discount usage
- Abuse by deal-hunters who repeatedly access and share codes
- Decreased perceived value of your products if discounts become too predictable
- SEO and indexing risks if search engines crawl and expose discount pages
To prevent misuse, consider:
✅ Implementing time-based restrictions (e.g., one discount per session)
✅ Using cookies or IP tracking to limit repeated access
✅ Displaying different discounts based on user engagement levels
✅ Monitoring analytics to detect unusual discount activity
By actively monitoring your 404 page and its dynamic features, you protect your business while still offering a great experience to genuine users. 🚀
404 pages for collecting email addresses
If you’re already collecting email addresses on your e-commerce site, you probably know that offering an incentive can significantly boost signup conversions.
A recent consumer study found that over 80% of shoppers sign up for email lists specifically to receive discounts and special offers.
So why not turn your 404 error page into an opportunity?
By offering a discount coupon, you can:
✅ Reduce frustration when visitors land on a broken page
✅ Encourage them to continue shopping instead of leaving
✅ Collect their email addresses, giving you another chance to re-engage them through email marketing
Ban.do includes a fun illustration, a search bar, and an email signup form on their 404 page.
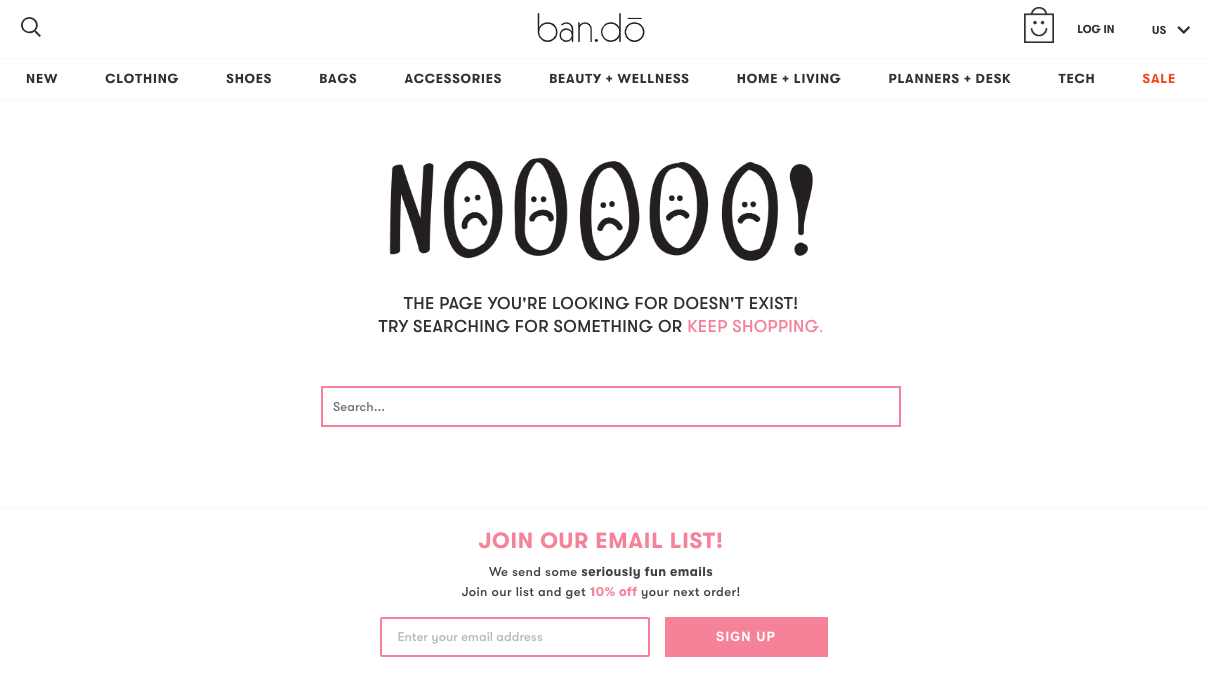
While this is a step in the right direction, there’s a disconnect between the error message, the search bar, and the reason for signing up. The incentive (10% off) is appealing, but it would be far more effective if they showcased top-selling products or gave a stronger reason to claim the discount.
💡 A simple improvement:
Instead of a generic signup prompt, customize the copy to communicate regret and compensation.
For example:
📝 “Oops! Looks like you hit a dead end. Let us make it up to you with an exclusive discount code.”
This acknowledges the visitor’s frustration, turns it into a positive experience, and piques curiosity—making them more likely to sign up.
A better example – Vero Moda
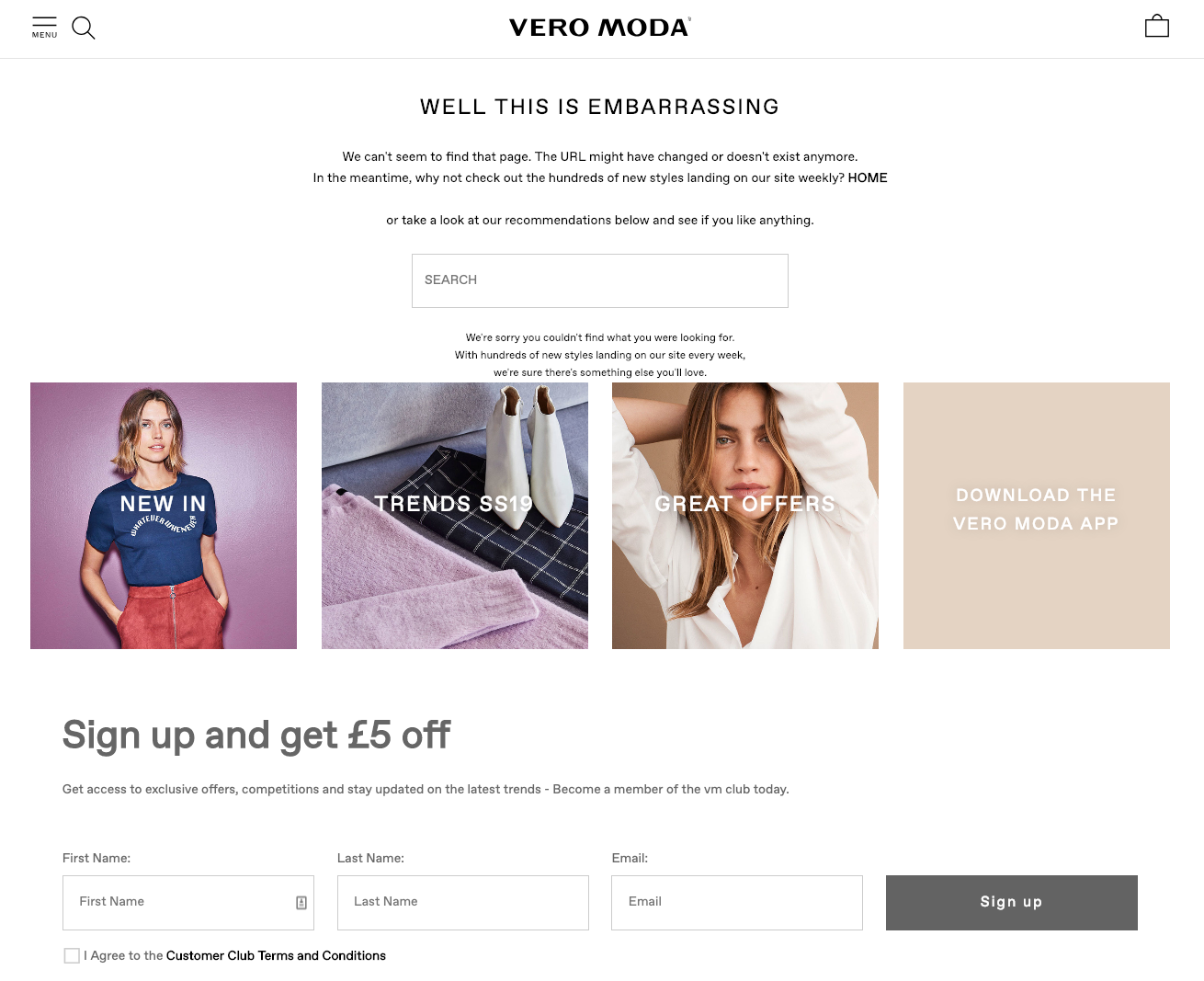
Vero Moda’s 404 page follows a logical flow that enhances user experience:
1️⃣ First, they acknowledge the error and provide an explanation.
2️⃣ Next, they offer navigation options like a search bar and links to key product categories such as “New In,” “Trends,” and “Great Offers.”
3️⃣ Finally, they offer an email signup incentive, where users can stay updated on trends, sales, and new arrivals—plus get a £5 discount.
This clear and structured approach gives visitors multiple actions to take without overwhelming them with too many choices.
Instead of treating 404 pages as dead ends, use them as an opportunity to re-engage visitors, collect emails, and even drive sales. A well-crafted email signup offer can turn lost traffic into loyal customers—and that’s a win-win. 🚀
Inject humor into your 404 page
Landing on a “page not found” can be frustrating.
But you can turn that frustration into a memorable moment by adding a touch of humor.
If humor fits your brand personality, it’s a great way to make your 404 page more enjoyable – instead of just another dead end.
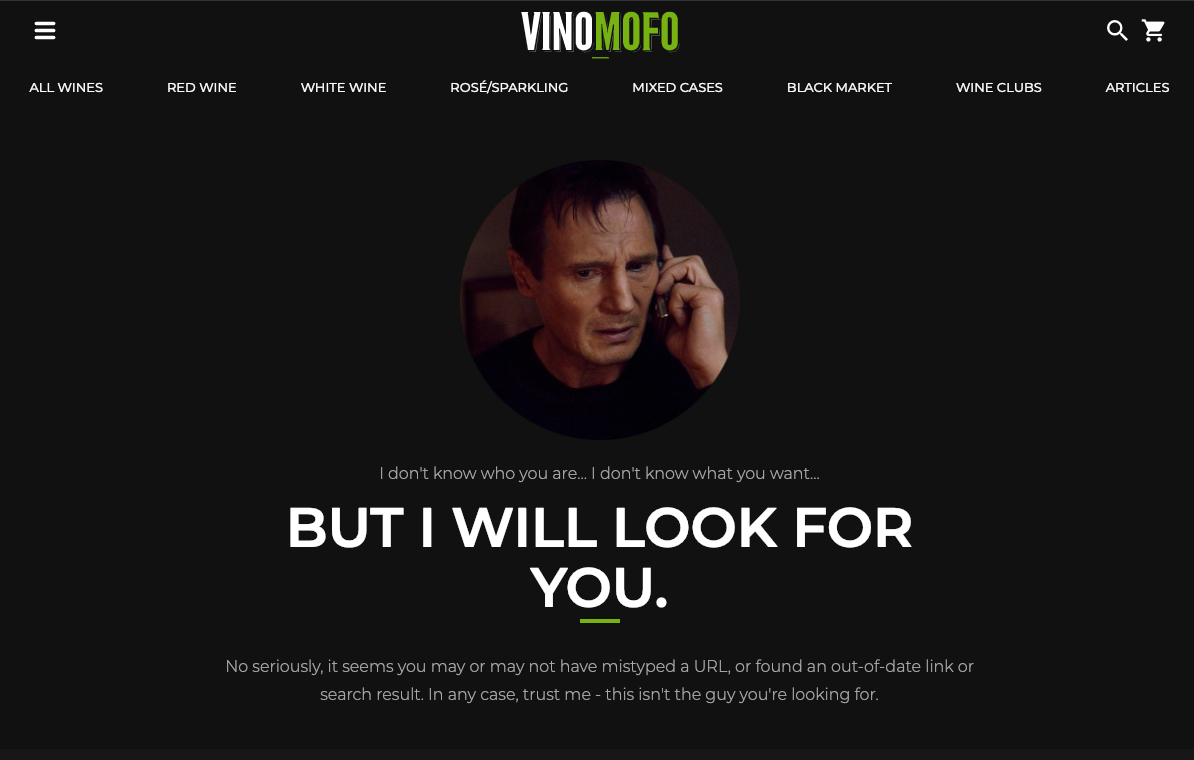
Vinomofo uses Liam Neeson’s famous lines from the movie Taken to create a lighthearted and relatable experience for visitors landing on their 404 page. This approach works well for them because it aligns with their brand’s overall tone and personality.
Of course, not every e-commerce business can or should take this route, but understanding your audience allows you to craft a message that resonates with them. A well-thought-out 404 page can ease frustration and keep visitors engaged rather than pushing them to leave.
That said, while Vinomofo does a great job setting the tone, its 404 page could be even more effective by guiding visitors to a product page or offering a search option after breaking the tension.
A funny message, an engaging animation, or a lighthearted joke can quickly change the mood and keep users engaged.
You can add other content people could engage/like/identify with.